Triển khai seq2seq với Pytorch
Bài viết này giới thiệu cách sử dụng Pytorch để xây dựng mô hình seq2seq và triển khai một ứng dụng dịch máy đơn giản, vui lòng đọc sơ qua bài báo sau trước, Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation(2014), để hiểu rõ cấu trúc seq2seq hoạt động như thế nào, sau đó đọc bài viết này để đạt được hiệu quả gấp đôi chỉ với một nửa công sức.

Bài viết này giới thiệu cách sử dụng Pytorch để xây dựng mô hình seq2seq và triển khai một ứng dụng dịch máy đơn giản, vui lòng đọc sơ qua bài báo sau trước, Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation(2014), để hiểu rõ cấu trúc seq2seq hoạt động như thế nào, sau đó đọc bài viết này để đạt được hiệu quả gấp đôi chỉ với một nửa công sức.
Tôi đã thấy rất nhiều sơ đồ cấu trúc mạng seq2seq và tôi cảm thấy sơ đồ này do Pytorch cung cấp là dễ hiểu nhất.
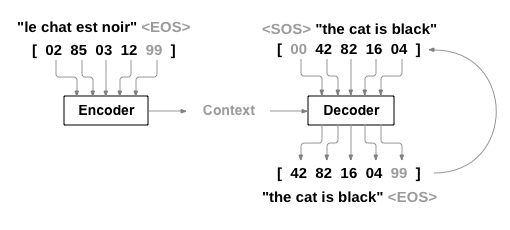
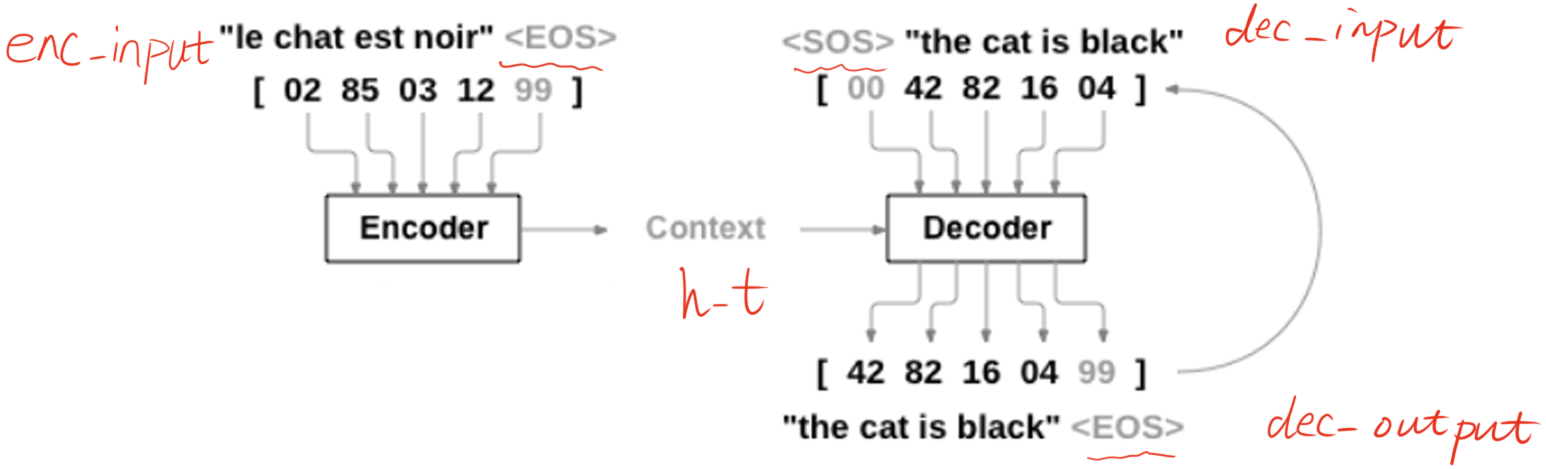
Trước hết, từ hình trên ta có thể thấy rõ ràng, seq2seq cần hoạt động trên ba “biến”, khác với tất cả các cấu trúc mạng mà tôi đã tiếp xúc trước đây. Chúng ta gọi đầu vào cho Encoder là enc_input, đầu vào cho Decoder là dec_input và đầu ra của Decoder là dec_output. Phần sau đây sử dụng một ví dụ cụ thể để minh họa cho toàn bộ quy trình thực hiện của seq2seq.
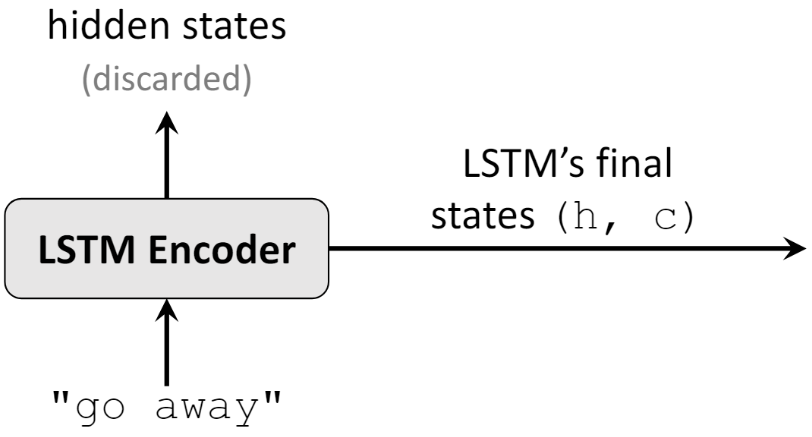
Hình bên dưới là cấu trúc Encoder cấu tạo từ LTSM, đầu vào là từng chữ cái (bao gồm cả dấu cách) trong “go away”, chúng ta cần thông tin của hidden state ở thời điểm cuối cùng, bao gồm \(h_{t}\) và \(c_{t}\).
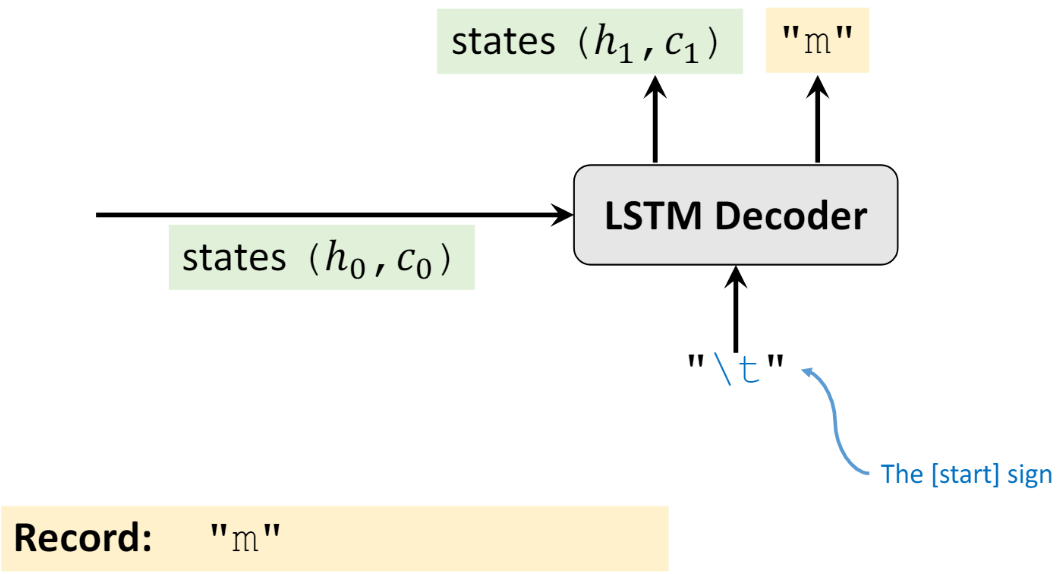
Sau đó sử dụng đầu ra gồm \(h_{t}\) và \(c_{t}\) làm đầu vào cho hidden state đầu tiên của Decoder là \(h_{0}, c_{0}\), như hình bên dưới. Đồng thời, lớp đầu vào (input layer) đầu của Decoder sẽ được nhập một ký tự đại diện cho phần đầu của câu (Do người dùng tự định nghĩa có thể là “<SOS>”, “\t”, “S”, …. đều được chấp nhận. Ở đây, tôi lấy “\t” làm ví dụ), và sau đó nhận đầu ra “m”, và một hidden state mới \(h_{1}\) và \(c_{1}\)
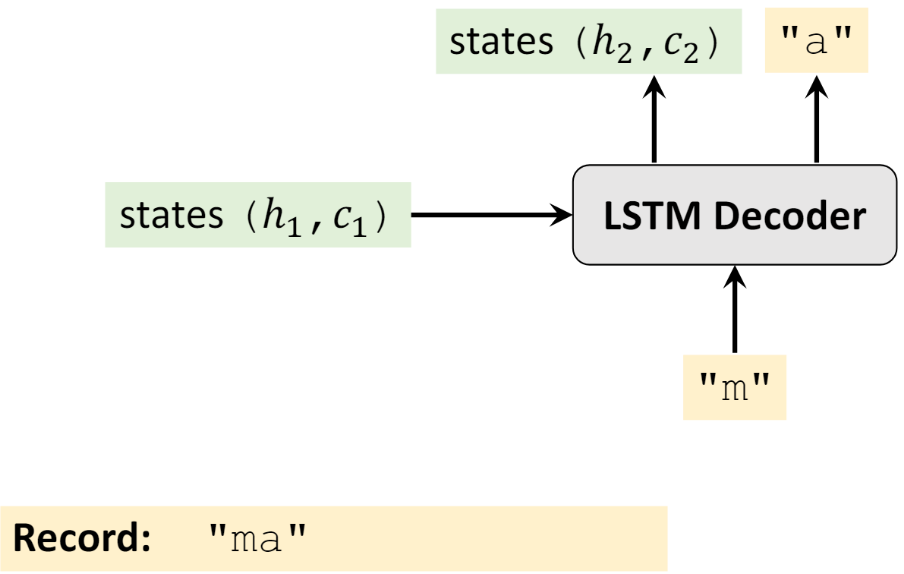
Sau đó lấy \(h_{1}\), \(c_{1}\) và “m” làm đầu vào, nhận đầu ra là “a”, và một hidden state mới \(h_{2}\) và \(c_{2}\)
Lặp lại các bước trên cho đến khi ký tự kết thúc của câu cuối cùng được xuất ra (do người dùng xác định, “<EOS>”, “\n”, “E”, … ở đây tôi lấy “\n” làm ví dụ).
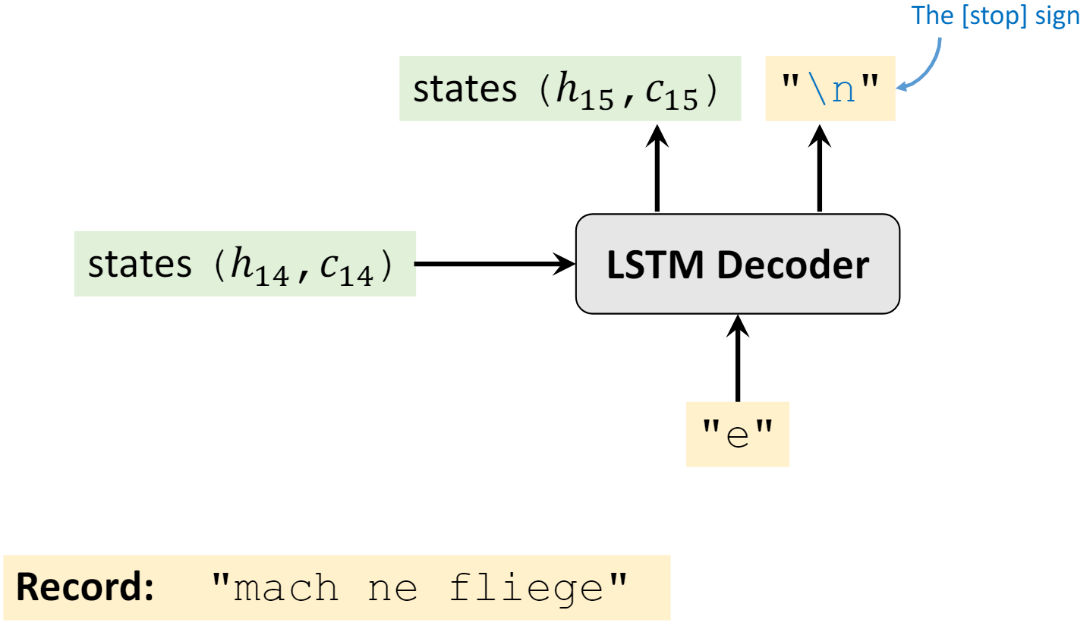
Trong phần Decoder, bạn sẽ có thể có những câu hỏi sau và tôi sẽ trả lời chúng theo hiểu biết cá nhân.
- Tôi phài làm như thế nào nếu Decoder không thể dừng lại trong quá trình đào tạo? Tức là ký tự kết thúc của câu không bao giờ được đưa ra.
- Đầu tiên, trong quá trình huấn luyện, độ dài của câu mà Decoder sẽ xuất ra sẽ được biết. Giả sử thời điểm hiện tại đã đến ký tự cuối cùng của độ dài câu và dự đoán không phải là ký tự kết thúc thì cũng không sao, chỉ dừng lại ở đây và tính toán tổn thất.
- Tôi phải làm như thế nào nếu Decocder không thể dừng lại trong quá trình kiểm tra? Ví dụ, dự đoán là “wasd s w \n sdsw \n …… (tiếp tục sinh từ)”
- Nó sẽ không dừng lại, vì trong quá trình kiểm tra, Decoder cũng có đầu vào, nhưng đầu vào này có rất nhiều placeholder vô nghĩa, chẳng hạn rất nhiều “<pad>”. Vì Decoder phải có đầu ra có độ dài hữu hạn. Khi đó bạn chỉ lấy tất cả các ký tự trước ký tự kết thúc đầu tiên. Ví dụ trên kết quả dự đoán cuối cùng là “wasd s w”.
- Mối quan hệ giữa đầu vào và đầu ra của Decoder, tức là
dec_inputvàdec_outputlà gì?- Trong quá trình huấn luyện, bất kể Decoder sinh ra kí tự nào tại thời điểm hiện tại, Decoder tại thời điểm tiếp theo sẽ nhập theo “kế hoạch” ban đầu. Ví dụ: giả sử
dec_input = "\twasted", sau khi nhập “\t” lần đầu, Decoder sẽ xuất ra chữ “m”, ghi lại thôi, nó sẽ không ảnh hưởng đến thời điểm tiếp theo khi Decoder tiếp tục nhập chữ “w”. - Trong quá trình valid và testing, đầu ra của Decoder tại mỗi thời điểm sẽ ảnh hưởng đến đầu vào, vì trong quá trình valid và testing, mạng không thể nhìn thấy kết quả nên chỉ tiến hành theo vòng lặp. Ví dụ, bây giờ tôi muốn dịch từ “wasted” trong tiếng anh sang tiếng “lãng phí” trong tiếng việt. Sau đó, Decoder bắt đầu với việc nhập ký tự “\t”, nhận kết quả đầu ra nếu là “m”, tại thời điểm tiếp theo, Decoder sẽ nhập “m”, nhận đầu ra, nếu là “a”, sau đó nhận “a” là đầu vào, nhận đầu ra, … và cứ thế cho đến khi gặp kí tự cuối cùng hoặc đạt độ dài tối đa. Mặc dù từ sinh ra không đúng nhưng mong đợi nhưng phải chấp nhận thôi
 .
.
- Trong quá trình huấn luyện, bất kể Decoder sinh ra kí tự nào tại thời điểm hiện tại, Decoder tại thời điểm tiếp theo sẽ nhập theo “kế hoạch” ban đầu. Ví dụ: giả sử
Hơi lạc đề một chút, cá nhân tôi nghĩ seq2seq rất giống với AutoEncoder.
Hãy bắt đầu giải thích mã
Đầu tiên, import thư viện, ở đây tôi dùng ‘S’ làm ký tự bắt đầu và ‘E’ làm ký tự kết thúc, nếu đầu vào hoặc đầu ra quá ngắn, tôi sẽ padding nó bằng ký tự ‘?’.
# code by Tae Hwan Jung(Jeff Jung) @graykode, modify by zhaospei
import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as Data
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# ?: Symbol that will fill in blank sequence if current batch data size is short than n_step
Xác định tập dữ liệu và các tham số tập dữ liệu ở đây rất đơn giản, có thể coi như một công việc dịch thuật, chỉ là dịch tiếng Anh sang tiếng Anh.
n_step` là độ dài của từ dài nhất, tất cả các từ khác không đủ dài sẽ được padding bằng ‘?’.
letter = [c for c in 'SE?abcdefghijklmnopqrstuvwxyz']
letter2idx = {n: i for i, n in enumerate(letter)}
seq_data = [['man', 'women'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]
# Seq2Seq Parameter
n_step = max([max(len(i), len(j)) for i, j in seq_data]) # max_len(=5)
n_hidden = 128
n_class = len(letter2idx) # classfication problem
batch_size = 3
Sau đây là xử lý dữ liệu, trước tên là xử lý các từ không đủ độ dài, sử dụng ký tự ‘?’ để padding; Sau đó thêm flag kết thúc ‘E’ vào cuối dữ liệu đầu vào của Encoder, thêm flag bắt đầu ‘S’ vào đầu dữ liệu đầu vào của Decoder và flag kết thúc ‘E’ vào cuối dữ liệu đầu ra của Decoder. Xem hình phía dưới để hiểu rõ hơn.
def make_data(seq_data):
enc_input_all, dec_input_all, dec_output_all = [], [], []
for seq in seq_data:
for i in range(2):
seq[i] = seq[i] + '?' * (n_step - len(seq[i])) # 'man??', 'women'
enc_input = [letter2idx[n] for n in (seq[0] + 'E')] # ['m', 'a', 'n', '?', '?', 'E']
dec_input = [letter2idx[n] for n in ('S' + seq[1])] # ['S', 'w', 'o', 'm', 'e', 'n']
dec_output = [letter2idx[n] for n in (seq[1] + 'E')] # ['w', 'o', 'm', 'e', 'n', 'E']
enc_input_all.append(np.eye(n_class)[enc_input])
dec_input_all.append(np.eye(n_class)[dec_input])
dec_output_all.append(dec_output) # not one-hot
# make tensor
return torch.Tensor(enc_input_all), torch.Tensor(dec_input_all), torch.LongTensor(dec_output_all)
'''
enc_input_all: [6, n_step+1 (because of 'E'), n_class]
dec_input_all: [6, n_step+1 (because of 'S'), n_class]
dec_output_all: [6, n_step+1 (because of 'E')]
'''
enc_input_all, dec_input_all, dec_output_all = make_data(seq_data)
Ví có ba dữ liệu trả về ở đây, vì vậy cần tùy chỉnh Dataset, cụ thể là kế thừa lớp torch.utils.data.Dataset, sau đó triển khai các phương thức __len__ và __getitem__ bên trong.
class TranslateDataSet(Data.Dataset):
def __init__(self, enc_input_all, dec_input_all, dec_output_all):
self.enc_input_all = enc_input_all
self.dec_input_all = dec_input_all
self.dec_output_all = dec_output_all
def __len__(self): # return dataset size
return len(self.enc_input_all)
def __getitem__(self, idx):
return self.enc_input_all[idx], self.dec_input_all[idx], self.dec_output_all[idx]
loader = Data.DataLoader(TranslateDataSet(enc_input_all, dec_input_all, dec_output_all), batch_size, True)
Xác định mô hình seq2seq bên dưới, tôi sử dụng RNN đơn giản làm Encoder và Decoder. Nếu bạn đã quen thuộc với RNN thì thực sự không có gì phải nói về việc xác định cấu trúc mạng, tôi cũng đã viết nhận xét rất rõ ràng, bao gồm cả những thay đổi về kích thước dữ liệu.
# Model
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq, self).__init__()
self.encoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # encoder
self.decoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # decoder
self.fc = nn.Linear(n_hidden, n_class)
def forward(self, enc_input, enc_hidden, dec_input):
# enc_input(=input_batch): [batch_size, n_step+1, n_class]
# dec_inpu(=output_batch): [batch_size, n_step+1, n_class]
enc_input = enc_input.transpose(0, 1) # enc_input: [n_step+1, batch_size, n_class]
dec_input = dec_input.transpose(0, 1) # dec_input: [n_step+1, batch_size, n_class]
# h_t : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
_, h_t = self.encoder(enc_input, enc_hidden)
# outputs : [n_step+1, batch_size, num_directions(=1) * n_hidden(=128)]
outputs, _ = self.decoder(dec_input, h_t)
model = self.fc(outputs) # model : [n_step+1, batch_size, n_class]
return model
model = Seq2Seq().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
Sau đây là phần training. Vì giá trị đầu ra là dữ liệu ba chiều nên việc tính toán loss đòi hỏi phải tính toán từng mẫu riêng biệt, do đó có mã vòng for sau đây.
for epoch in range(5000):
for enc_input_batch, dec_input_batch, dec_output_batch in loader:
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
h_0 = torch.zeros(1, batch_size, n_hidden).to(device)
(enc_input_batch, dec_intput_batch, dec_output_batch) = (enc_input_batch.to(device), dec_input_batch.to(device), dec_output_batch.to(device))
# enc_input_batch : [batch_size, n_step+1, n_class]
# dec_intput_batch : [batch_size, n_step+1, n_class]
# dec_output_batch : [batch_size, n_step+1], not one-hot
pred = model(enc_input_batch, h_0, dec_intput_batch)
# pred : [n_step+1, batch_size, n_class]
pred = pred.transpose(0, 1) # [batch_size, n_step+1(=6), n_class]
loss = 0
for i in range(len(dec_output_batch)):
# pred[i] : [n_step+1, n_class]
# dec_output_batch[i] : [n_step+1]
loss += criterion(pred[i], dec_output_batch[i])
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
Như có thể thấy từ mã testing bên dưới, trong quá trình testing, đầu vào của Decoder là một phần giữ chỗ vô nghĩa và độ dài của vị trí bị chiếm giữ là độ dài tối đa n_step. Và tìm vị trí của dấu kết thúc đầu tiên ở đầu ra, chặn tất cả các ký tự trước nó.
# Test
def translate(word):
enc_input, dec_input, _ = make_data([[word, '?' * n_step]])
enc_input, dec_input = enc_input.to(device), dec_input.to(device)
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
hidden = torch.zeros(1, 1, n_hidden).to(device)
output = model(enc_input, hidden, dec_input)
# output : [n_step+1, batch_size, n_class]
predict = output.data.max(2, keepdim=True)[1] # select n_class dimension
decoded = [letter[i] for i in predict]
translated = ''.join(decoded[:decoded.index('E')])
return translated.replace('?', '')
print('test')
print('man ->', translate('man'))
print('mans ->', translate('mans'))
print('king ->', translate('king'))
print('black ->', translate('black'))
print('up ->', translate('up'))
Mã hoàn chỉnh như sau
Phần thực thi bạn có thể xem tại notebook trên kaggle tại https://www.kaggle.com/code/overvisual/seq2seq-torch?scriptVersionId=145596925
# code by Tae Hwan Jung(Jeff Jung) @graykode, modify by zhaospei
import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as Data
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# ?: Symbol that will fill in blank sequence if current batch data size is short than n_step
letter = [c for c in 'SE?abcdefghijklmnopqrstuvwxyz']
letter2idx = {n: i for i, n in enumerate(letter)}
seq_data = [['man', 'women'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]
# Seq2Seq Parameter
n_step = max([max(len(i), len(j)) for i, j in seq_data]) # max_len(=5)
n_hidden = 128
n_class = len(letter2idx) # classfication problem
batch_size = 3
def make_data(seq_data):
enc_input_all, dec_input_all, dec_output_all = [], [], []
for seq in seq_data:
for i in range(2):
seq[i] = seq[i] + '?' * (n_step - len(seq[i])) # 'man??', 'women'
enc_input = [letter2idx[n] for n in (seq[0] + 'E')] # ['m', 'a', 'n', '?', '?', 'E']
dec_input = [letter2idx[n] for n in ('S' + seq[1])] # ['S', 'w', 'o', 'm', 'e', 'n']
dec_output = [letter2idx[n] for n in (seq[1] + 'E')] # ['w', 'o', 'm', 'e', 'n', 'E']
enc_input_all.append(np.eye(n_class)[enc_input])
dec_input_all.append(np.eye(n_class)[dec_input])
dec_output_all.append(dec_output) # not one-hot
# make tensor
return torch.Tensor(enc_input_all), torch.Tensor(dec_input_all), torch.LongTensor(dec_output_all)
'''
enc_input_all: [6, n_step+1 (because of 'E'), n_class]
dec_input_all: [6, n_step+1 (because of 'S'), n_class]
dec_output_all: [6, n_step+1 (because of 'E')]
'''
enc_input_all, dec_input_all, dec_output_all = make_data(seq_data)
class TranslateDataSet(Data.Dataset):
def __init__(self, enc_input_all, dec_input_all, dec_output_all):
self.enc_input_all = enc_input_all
self.dec_input_all = dec_input_all
self.dec_output_all = dec_output_all
def __len__(self): # return dataset size
return len(self.enc_input_all)
def __getitem__(self, idx):
return self.enc_input_all[idx], self.dec_input_all[idx], self.dec_output_all[idx]
loader = Data.DataLoader(TranslateDataSet(enc_input_all, dec_input_all, dec_output_all), batch_size, True)
# Model
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq, self).__init__()
self.encoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # encoder
self.decoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # decoder
self.fc = nn.Linear(n_hidden, n_class)
def forward(self, enc_input, enc_hidden, dec_input):
# enc_input(=input_batch): [batch_size, n_step+1, n_class]
# dec_inpu(=output_batch): [batch_size, n_step+1, n_class]
enc_input = enc_input.transpose(0, 1) # enc_input: [n_step+1, batch_size, n_class]
dec_input = dec_input.transpose(0, 1) # dec_input: [n_step+1, batch_size, n_class]
# h_t : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
_, h_t = self.encoder(enc_input, enc_hidden)
# outputs : [n_step+1, batch_size, num_directions(=1) * n_hidden(=128)]
outputs, _ = self.decoder(dec_input, h_t)
model = self.fc(outputs) # model : [n_step+1, batch_size, n_class]
return model
model = Seq2Seq().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(5000):
for enc_input_batch, dec_input_batch, dec_output_batch in loader:
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
h_0 = torch.zeros(1, batch_size, n_hidden).to(device)
(enc_input_batch, dec_intput_batch, dec_output_batch) = (enc_input_batch.to(device), dec_input_batch.to(device), dec_output_batch.to(device))
# enc_input_batch : [batch_size, n_step+1, n_class]
# dec_intput_batch : [batch_size, n_step+1, n_class]
# dec_output_batch : [batch_size, n_step+1], not one-hot
pred = model(enc_input_batch, h_0, dec_intput_batch)
# pred : [n_step+1, batch_size, n_class]
pred = pred.transpose(0, 1) # [batch_size, n_step+1(=6), n_class]
loss = 0
for i in range(len(dec_output_batch)):
# pred[i] : [n_step+1, n_class]
# dec_output_batch[i] : [n_step+1]
loss += criterion(pred[i], dec_output_batch[i])
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Test
def translate(word):
enc_input, dec_input, _ = make_data([[word, '?' * n_step]])
enc_input, dec_input = enc_input.to(device), dec_input.to(device)
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
hidden = torch.zeros(1, 1, n_hidden).to(device)
output = model(enc_input, hidden, dec_input)
# output : [n_step+1, batch_size, n_class]
predict = output.data.max(2, keepdim=True)[1] # select n_class dimension
decoded = [letter[i] for i in predict]
translated = ''.join(decoded[:decoded.index('E')])
return translated.replace('?', '')
print('test')
print('man ->', translate('man'))
print('mans ->', translate('mans'))
print('king ->', translate('king'))
print('black ->', translate('black'))
print('up ->', translate('up'))
Tham khảo
[1] https://www.kaggle.com/code/overvisual/seq2seq-torch?scriptVersionId=145596925
Last Update: October 20, 2023

Mangaldeep Singh is a blogger, software engineer and the main coordinator of this blog, he has lots of ideas and won't hesitate to use them! From ❤️ India.
