
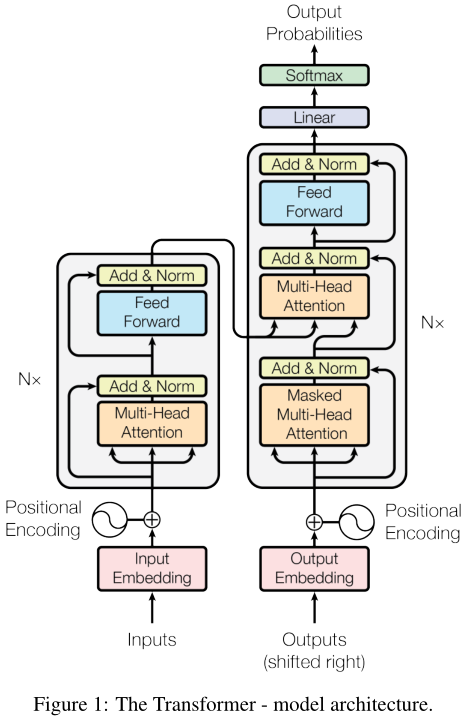
Transformer là mô hình seq2seq được Google Brain đề xuất trong một bài báo xuất bản vào cuối năm 2017. Giờ đây, nó đã đạt được nhiều ứng dụng và tiện ích mở rộng và BERT là mô hình ngôn ngữ được đào tạo trước có nguồn gốc từ Transformer.
Việc đào tạo RNN truyền thống là nối tiếp và nó phải đợi từ hiện tại được xử lý trước khi có thể xử lý từ tiếp theo. Transformer được huấn luyện song song, tức là tất cả các từ đều được huấn luyện cùng một lúc, điêu này làm tăng đáng kể hiệu quả tính toán.
# Self-Attention
Scaled Dot-Product Attention là tích chấm chuẩn hóa Attention, chi tiết cụ thể được thể hiện trong hình.
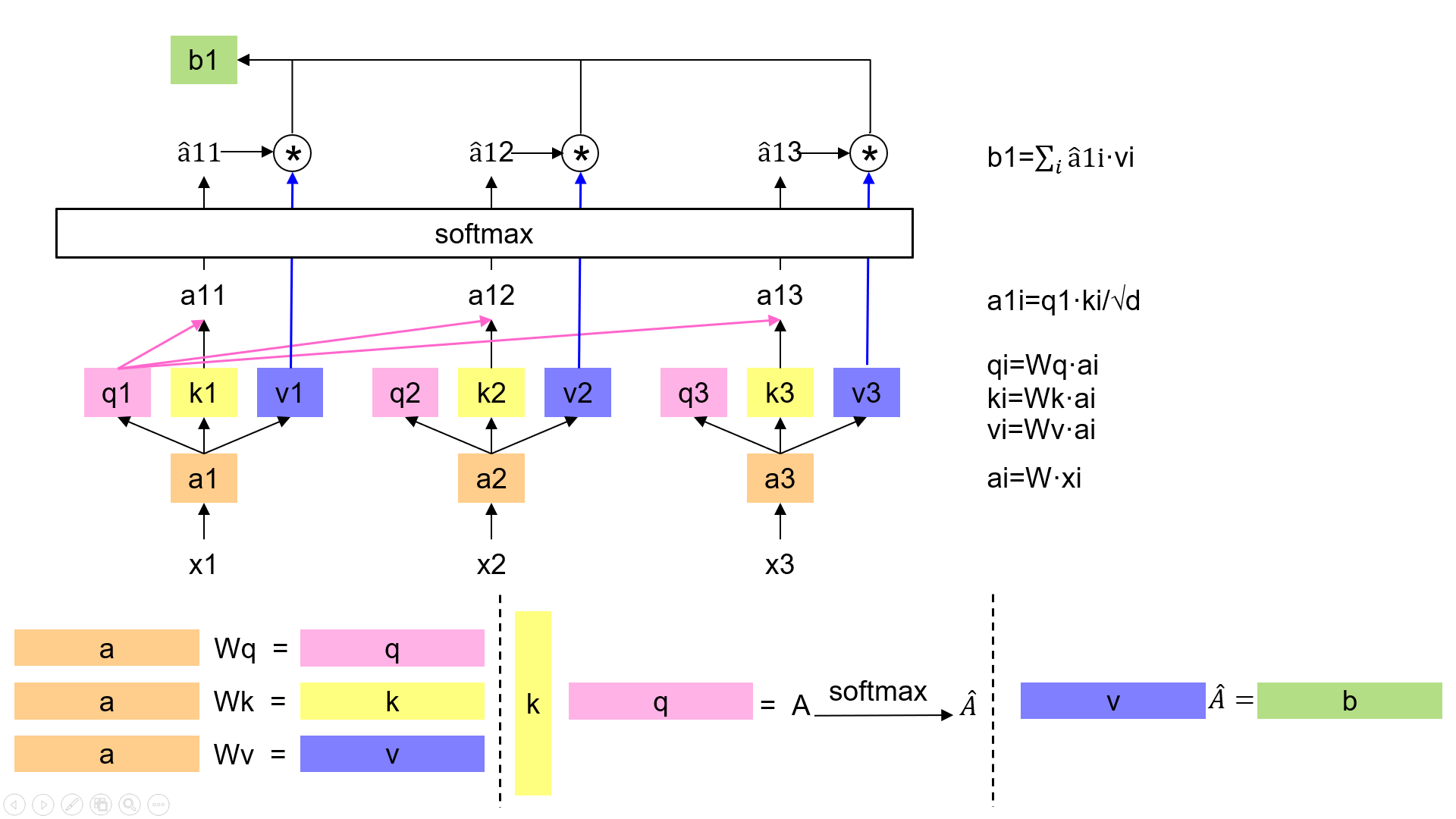
Sự chú ý của nhiều đầu vào sử dụng nhiều bộ trọng số (weights) (\(W_q,W_k,W_v\)), ghép lại cho ra kết quả cuối cùng.
trong đó
\[head_i=Attention(QW^Q_i,KW^K_i,VW^V_i)\]Trong đó \(h = 8\), \(d_q=d_k=d_v=d_{model}/4=64\).
# Encoder
Encoder được xếp chồng lên nhau bởi sáu lớp giống hệt nhau, mỗi lớp bao gồm hai lớp con - cơ chế tự chú ý nhiều đầu (multi-head self-attention mechanism) và mạng nơ ron vị trí chuyển tiếp được kết nối đầy đủ (position-wise fully connected feed-forward network). Mỗi lớp con sử dụng các kết nối dư (residual connection) và lớp chuẩn hóa (layer normalization). Kích thước đầu ra của các lớp con là \(d_{model} = 512\).
Đầu ra của lớp con có thể được biểu diễn dưới dạng:
\[LayerNorm(x+Sublayer(x))\]position-wise fully connected feed-forward network
Mạng nơ-ron chuyển tiếp được kết nối đầy đủ (position-wise fully connected feed-forward network) bao gồm hai phép biến đổi tuyến tính với kích hoạt ReLU ở giữa.
Kích thước lớp bên trong (inner-layer) là 2048.
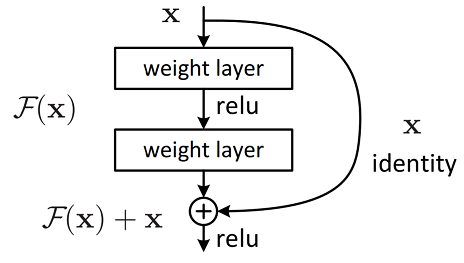
residual connection
Mạng dư (Residual Network), các kết nối tắt có khả năng bỏ qua một hoặc nhiều lớp, do sự tồn tại của kết nối tắt nên hiệu suất của mạng sâu (có nhiều lớp) không kém hơn so với các mạng nông (mạng có ít lớp). Phương pháp này giải quyết vấn đề suy thoái do các lớp chập xếp chồng lên nhau gây ra, số lượng lớp của mạng nơ-ron tích chập đã được tăng lên rất nhiều lên hàng trăm lớp, và cải thiện đáng kể hiệu suất của mạng thần kinh tích chập (resnet).
Batch Norm và Layer Norm
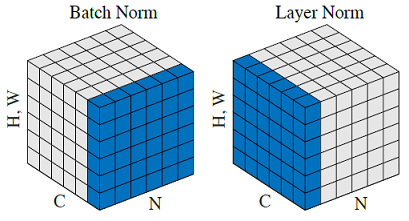
Đặt kích thước hình ảnh đầu vào là \([N, C, H, W]\):
Batch Norm, chuẩn hóa theo từng batch NHW, là để chuẩn hóa đầu vào từng kênh đơn, đều này không hiệu quả đối vớibatch-sizenhỏ.Layer Norm, chuẩn hóa theo từng layer CHW, là để chuẩn hóa đầu vào ở mỗi độ sâu, chủ yếu có tác dụng rõ ràng trên RNN.
Sự hiểu biết cá nhân:
- Dành cho CNN, nếu hạt nhân tích chập quét hình ảnh đầu vào, nó được tính là thao tác tích chập, cần có tổng thao tác batchsize. Do đó, chuẩn hóa cần được thực hiện theo batch.
- Dành cho RNN, batchsize thường là 1, số vòng lặp là số độ dài đầu vào (số channel). Do đó, chuẩn hóa cần được thực hiện theo channel.
Toàn bộ kiến trúc Encoder
input & positional embedding
\[X=Embedding-Lookup(X)+Positional-Encoding\]multi-head attention
\[Q=Linear_q(X)=XW_q\] \[K=Linear_q(X)=XW_k\] \[V=Linear_v(X)=XW_v\] \[X_{attention}=Self-Attention(Q,K,V)\]add & norm
\[X_{attention}=LayerNorm(X+X_{attention})\]feed forward
\[X_{hidden}=Linear(ReLU(Linear(X_{attention})))\]add & norm
\[X_{hidden}=LayerNorm(X_{hidden}+X_{attention})\]multi-head attention trong Encoder là một cơ chế tự chú ý (self-attention mechanism). \(k\), \(q\) và \(v\) trong cơ chế tự chú ý đều xuất phát từ cùng một vị trí, mỗi lớp của Encoder có thể nhận được tất cả vị trí của lớp trước.
# Decoder
Decoder bao gồm sáu lớp giống hệt xếp chồng lên nhau; trong Multi-head Attention, \(q\) được đến từ lớp trước đó của Decoder, k và v đến từ đầu ra của Encoder. Điều cho phép mỗi vị trí trong Decoder nhận biết được tất cả các vị trí của chuỗi đầu vào.
Ngoài hai lớp con trong Encoder, Decoder thêm một lớp con mới xử lý đầu ra của Encoder - masked multi-head self-attention mechanism. Encoder trong seq2seq truyền thống sử dụng mô hình RNN, vì vậy nếu các từ tại thời điểm t được nhập vào trong quá trình huấn luyện thì mô hình sẽ không thể nhìn thấy các từ trước đó vào các thời điểm trong tương lai, bởi vì RNN hoạt động theo thời gian và chỉ khi thao tác tại thời điểm t hoàn thành, chỉ khi đó ta mới có thể nhìn thấy các từ tại thời điểm t + 1. Và Transformer Decoder đã không sử dụng RNN, thay đổi sang Self-Attention, điều này tạo ra một vấn đề, trong quá trình huấn luyện, toàn bộ ground truth đã được hiển thị với Decoder, điều này rõ ràng là sai, chúng ta cần phải thực hiện một số xử lý trên đầu vào của Decoder, quá trình này được gọi là Mask - Đặt tất cả các giá trị sau postion thành \(-\infty\) trước khi vào softmax.
Ví dụ, ground truth của Decoder là “<start> I am fine”, chúng ta cho câu này vào bộ Decoder, sau khi Word Embedding và Positional Encoding, thực hiện phép biến đổi tuyến tính bậc 3 trên ma trận thu được \((W_Q,W_K,W_V)\) Sau đó thực hiện self-attention, trước tiên, nhận Scaled Scores thông qua \(\dfrac{Q×K^T}{\sqrt{d_k}}\), bước tiếp theo rất quan trọng, chúng ta cần mask theo Scaled Scores, ví dụ, khi nhập “I”, hiện tại mô hình chỉ biết thông tin của tất cả các từ trước đó của “I”, tức thông tin của “<start>” và “I”, không được phép biết được thông tin của các từ sau “I”. Lý do rất đơn giản, khi dự đoán là chúng ta dự đoán theo thứ tự từng chữ, làm sao có thể biết được thông tin của những từ sau trước khi dự đoán xong từ này? Mask rất đơn giản, đầu tiên tạo một ma trận có tam giác hoàn toàn phía dưới bằng 0 và tam giác hoàn tòan phía trên bằng âm vô cùng, sau đó chỉ cần thêm nó vào Scaled Scores.
# Word Embedding và Positional Embedding
Word Embedding
Phần nhúng từ sử dụng nhúng từ có thể học được, kích thước của nó là \(d_{model}\).
Hình thức mã hóa One-hot ngắn gọn, nhưng quá thưa thớt, nó không phản ánh sự giống nhau về nghĩa của từ. Vì vậy hãy sử dụng the Skip-Gram Model hoặc continuous bag of words model hoặc các nhúng từ khác có thể học được khác.
Positional Embedding
Bởi vì mô hình không bao gồm các cấu trúc tuần hoàn, vì vậy nắm bắt được các thông tin thứ tự tuần tự, ví dụ nếu \(K\) và \(V\) được xóa trộn theo từng hàng thì kết quả sau Attention sẽ giống nhau. Tuy nhiên, thông tin tuần tự rất quan trọng và thể hiện cấu trúc toàn cầu, do đó thông tin position tuyệt đối và tương đối của token tuần tự phải được sử dụng.
Nhúng vị trí tùy chinh
Một ý tưởng là lấy một số trong khoảng \([0, 1]\) và gán nó cho mỗi từ, trong đó 0 được trao cho từ đầu tiên, 1 cho từ cuối cùng, công thức cụ thể là \(PE=\dfrac{pos}{T−1}\). Vấn đề của việc gán theo công thức này là nó bị phụ thuộc và kích thước của văn bản. Tức là văn bản có số kí tự là 30. Khi đó theo công thức trên, thì khoảng cách giữa hai từ sẽ là 0.0333. Khi văn bản khác có số lượng kí từ < 30, thì con số 0.0333 vẫn mô tả đúng vị trí tương đối giữa chúng, tuy nhiên với văn bản > 30, ví dụ 90 thì 0.0333 đang gộp khoảng cách thực tế đang được phân tách bởi hai ký tự. Điều này rõ ràng là không phù hợp, vì sự khác biệt giống nhau không có nghĩa là giống nhau trong các câu khác nhau.
Một ý tưởng khác là gắn tuyến tính mỗi bước theo thời gian, nghĩa là từ đầu tiên được gán là 1, từ thứ hai được gán là 2, … Phương pháp này cũng có những vấn đề lớn: 1. Nó lớn hơn giá trị nhúng từ thông từ, có thể gây nhiễu cho mô hình; 2. Ký tự cuối cùng lớn hơn nhiều ký tự đầu tiên, sau khi hợp nhất với các từ nhúng, giá trị của các đặc trưng sẽ bị sai lệch.
Nhúng từ vị trí “lý tuởng”
Một lý tưởng là thiết kế nhúng vị trí phải đáp ứng những tiêu chí sau:
- Nó sẽ xuất ra mã hóa duy nhất cho mỗi từ.
- Sự khác biệt giữa hai từ phải nhất quán giữa các câu có độ dài khác nhau.
- Giá trị của nó phải được giới hạn.
Do đó việc nhúng vị trí sin và cosin đã được sử dụng cho Transformer.
Bây giờ hãy định nghĩa lại Positional Embedding, kích thước của việc nhúng vị trí là [max_sequence_length, embedding_dimension], kích thước của phần nhúng vị trí giống với kích thước của vector từ, đều bằng embedding_dimension. max_sequence_length là một hyperparameter, đề cập đến số lượng tối đa mà một câu bao gồm.
Kích thước của việc nhúng vị trí cũng giống như kích thước của việc nhúng từ, cùng là \(d_{model}\). Công thước tính toán của nó là:
\[PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})\] \[PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})\]Trong đó, \(pos\) đại diện cho chỉ mục vị trí, \(i\) đại diện cho chỉ số chiều. Nghĩa là mỗi chiều \(i\) của positional embedding pos tương ứng với một sóng sin.
Trong hình dưới này minh họa cho cách tính position embedding của tác giả với số chiều là 6. Giá trị của các vector tại mỗi vị trí được tính toán theo công thức ở hình dưới.
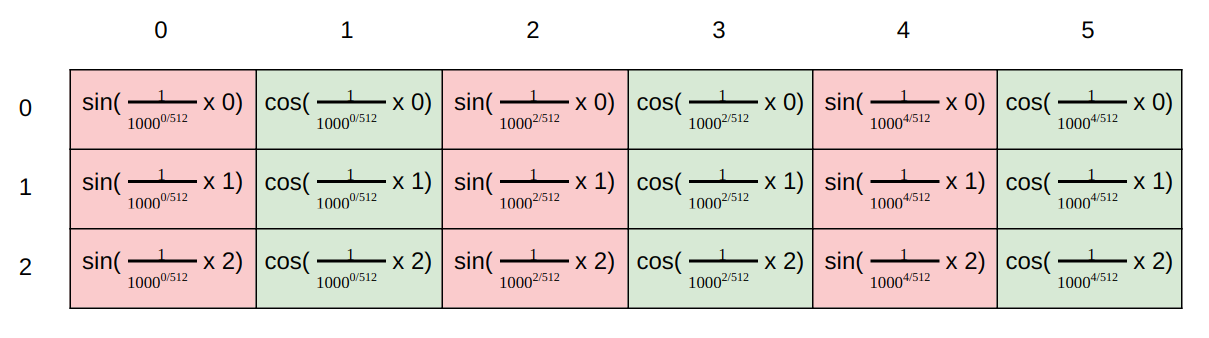
Bản thân việc nhúng vị trí là một thông tin vị trí tuyệt đối, nhưng trong ngôn ngữ, vị trí tương đối cũng rất quan trọng, bởi vì
\[sin(\alpha+\beta)=sin\alpha cos\beta+cos\alpha sin\beta\cos(\alpha+\beta)=cos\alpha cos\beta-sin\alpha sin\beta\]cho thấy vector tại vị trí \(p + k\) có thể được biểu diễn dưới dạng phép biến đổi tuyến tính của vectơ tại vị trí \(p\), điều này cung cấp khả năng thể hiện thông tin vị trí tương đối. Phiên bản hình sin cũng cho phép mô hình ngoại suy với độ dài chuỗi dài hơn so với độ dài chuỗi gặp phải trong quá trình huấn luyện.
# Q & A
Tại sao Transformer cần Multi-head Attention ?
Bài báo đề cập lý do việc tiến hành Multi-head Attention là để chia mô hình thành nhiều đầu để tạo thành nhiều không gian con, cho phép mô hình chú ý đến các khía cạnh khác nhau của thông tin và cuối cùng tổng hợp thông tin từ tất cả các khía cạnh. Trên thực tế, có thể hình dung bằng trực giác rằng nếu bạn tự thiết kế một mô hình như vậy, attention sẽ không chỉ được thực hiện một lần, kết quả tổng hợp của nhiều lần chú ý ít nhất có thể nâng cao mô hình và cũng có thể được so sánh với vai trò của việc sử dụng nhiều tích chập cùng lúc trong CNN, theo trực giác, sự chú ý của nhiều người đứng đầu giúp mạng nắm bắt được các tính năng/ thông tin phong phú hơn.
Ưu điểm của Transformer so với RNN/LSTM là gì? Tại sao?
- Các mô hình RNN không thể tính toán song song vì việc tính toán tại thời điểm T phụ thuộc vào kết quả tính toán của lớp ẩn tại thời điểm T - 1, còn việc tính toán tại thời điểm T - 1 lại phụ thuộc tính toán của lớp ẩn tại thời điểm T - 2.
- Khả năng trích xuất đặc trưng của Transformer tốt hơn so với các mô hình RNN.
Tại sao Transformer có thể thay thế seq2seq?
Từ thay thế ở đây hơi không phù hợp, seq2seq tuy cũ nhưng vẫn có chỗ đứng, vấn đề lớn nhất của seq2seq là ở chỗ Nén thông tin ở phía Encoder thành một vector có độ dài cố định và sử dụng nó làm đầu vào của trạng thái đầu tiên ở phía Decoder, để dự đoán trạng thái ẩn của từ đầu tiên (mã thông báo) ở phía Decoder. Khi chuỗi đầu vào tương đối dài, điều này rõ ràng sẽ mất rất nhiều thông tin ở phía Encoder và vector cố định sẽ được gửi đến phía Decoder cùng một lúc, bên Decoder không thể chú ý đến thông tin mà nó muốn chú ý. Mô hinh transformer không chỉ cải thiện đáng kể hai khuyết điểm này của mô hình seq2seq (Mô-đun attention tương tác nhiều đầu), và cũng giới thiệu mô-đun self-attention, trước tiên hãy để trình tự nguồn và trình tự đích được “tự liên kết”, trong trường hợp này, thông tin chứa trong embedding của trình tự nguồn và trình tự đích sẽ phong phú hơn và lớp FFN tiếp theo cũng nâng cao khả năng biểu đạt của mô hình, và tính toán song song của Transfomer vượt xa các model seq2seq.
Tham khảo
Last Update: October 8, 2023

Mangaldeep Singh is a blogger, software engineer and the main coordinator of this blog, he has lots of ideas and won't hesitate to use them! From ❤️ India.
