[NLP] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT dùng thiết kể để đào tạo sâu, biểu diễn hai chiều, dữ liệu không gán nhãn được sử dụng và thông tin ngữ cảnh song phương trái và phải được kết hợp (Tức context được xác định ở cả hai phía của từ)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Tiêu đề
Pre-training (Đào tạo trước): Nếu một mô hình được đào tạo trên một tập dữ liệu lớn nhưng mục đích chính là sử dụng cho nhiệm vụ khác (được gọi là Training), thì nhiệm vụ đào tạo mô hình đó được gọi là Pre-training.
Deep: rất dễ hiểu, chỉ là sâu thôi.
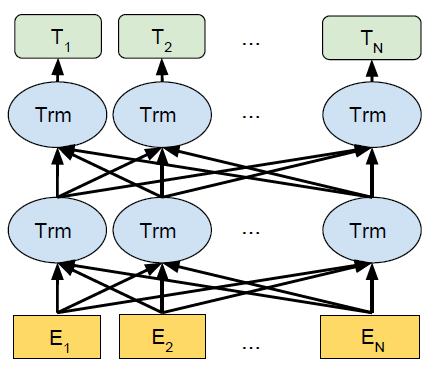
Bidirectional: nghĩa là có 2 chiều, được giải thích ở cuối bài viết.
Transformers: Mô hình học sâu được thiết kế dùng để phục vụ giải quyết nhiều bài toán trong xử lý ngôn ngữ tự nhiên và tiếng nói. Vui lòng xem thêm
Tóm lại, mô hình BERT là một mô hình Transfomers sâu 2 chiều, được sử dụng làm mô hình đào tạo trước để hiểu ngôn ngữ.
Abstract
BERT viết tắt của Bidirectional Encoder Representations from Transformers.
Như đã nói ở đoạn đầu, BERT dùng thiết kể để đào tạo sâu, biểu diễn hai chiều, dữ liệu không gán nhãn được sử dụng và thông tin ngữ cảnh song phương trái và phải được kết hợp (Tức context được xác định ở cả hai phía của từ). Do thiết kế tinh tế của BERT, nó chỉ cần thêm một lớp đầu ra bổ sung và thực hiện tinh chỉnh tương ứng, và nó có thể được áp dụng cho nhiểu tác vụ mà không cần thực hiên nhiều sửa đổi đối với các tác vụ cụ thể.
Introduction
Đào tạo trước đã trở nên phổ biến trong NLP. Ví dụ, trong bài toán nhận dạng thực thể có tên (NER), BERT không phải là mô hình đầu tiên được đề xuất, xét cho cùng chúng ta có thể dùng BERT ứng dụng trong CV - Compution Vision, nhưng BERT ứng dụng tốt nhất trong các bài toán NLP.
Khi sử dụng mô hình đào tạo trước để biểu diễn đặc trưng cho các tác vụ tiếp theo, thường có hai chiến lược, một chiến lược dựa trên các đặc trưng (feature-based) và chiến lược còn lại dựa trên tinh chỉnh (fine-tuning). Cả hai phương pháp đều sử dụng cùng một hàm mục tiêu trong quá trình đào tạo trước, đây là mô hình ngôn ngữ một chiều.
Dựa trên tính năng, cách làm tiêu biểu [ELMo], sử dụng kiến trúc RRN, đối với mỗi tác vụ xuôi dòng, xây dựng mạng thần kinh liên quan đến tác vụ hiện tại, biểu diễn đặc trưng được đào tạo trước, như một tính năng bổ sung, đưa nó vào mạng cùng với đầu vào ban đầu.
Dựa trên sự tinh chỉnh, cách làm tiêu biểu [GPT], giảm tham số cho một tác vụ cụ thể, khi đưa các tham số mô hình được huấn luyện trước vào dữ liệu xuôi dòng, tất cả các thông số sẽ được tinh chinh.
Sau đó tác giả thảo luận về những hạn chế của các phương pháp này, đặc biêt với phương pháp tinh chỉnh, do mô hình ngôn ngữ là một chiều nên có một số hạn chế trong việc lựa chọn kiến trúc. Ví dụ: trong GPT sử dụng kiến trúc từ trái sang phải. Theo cách nói của con người, khi đọc một câu, chúng ta chỉ có thể đọc từ trái sang phải. Trong một số nhiệm vụ, chẳng hạn như đánh giá cảm xúc của một câu (QA), … việc đọc từ phải sang trái hay trái sang phải được hợp pháp. Tác giả tin rằng việc đưa thông tin từ cả hai hướng vào cùng một lúc sẽ giúp nâng cao hiệu quả thực hiện.
(Tiếp tục viết trong tương lai xa…)
Last Update: October 5, 2023

Mangaldeep Singh is a blogger, software engineer and the main coordinator of this blog, he has lots of ideas and won't hesitate to use them! From ❤️ India.
