Lựa chọn đặc trưng trong học máy bằng kiểm tra Chi-Square
Lựa chọn đặc trưng là một trong những vấn đề quan trọng trong học máy, khi chúng ta có một đống cái đặc trưng và quyết định xem những đặc trưng nào là tốt nhất để xây dựng mô hình.

Lựa chọn đặc trưng là một trong những vấn đề quan trọng trong học máy, khi chúng ta có một đống cái đặc trưng và quyết định xem những đặc trưng nào là tốt nhất để xây dựng mô hình.
Có nhiều phương pháp để lựa chọn đặc trưng, trong bài viết này tôi sẽ đưa giải pháp thực hiện bằng Chi-Square.
Phân phối Chi-Square
Một biến ngẫu nhiên \(\chi\) tuân theo phân phối chi-square nếu nó có thể viết được viết dưới dạng tổng bình phương các biến chuẩn chuẩn hoá.
\[\chi^{2} = \sum_{}^{}Z_{i}^{2}\]Trong đó \(Z_{1}, Z_{2}, ...\) là các biến chuẩn chuẩn hoá.
Bậc tự do (Degrees of freedom)
Bậc tự do đề cập đến số lượng tối đa các giá trị độc lập logic, có quyền tự do thay đổi. Nói một cách đơn giản, nó có thể được định nghĩa là tổng số mẫu dữ liệu trừ đi số lượng ràng buộc độc lập áp đặt cho các mẫu dữ liệu.
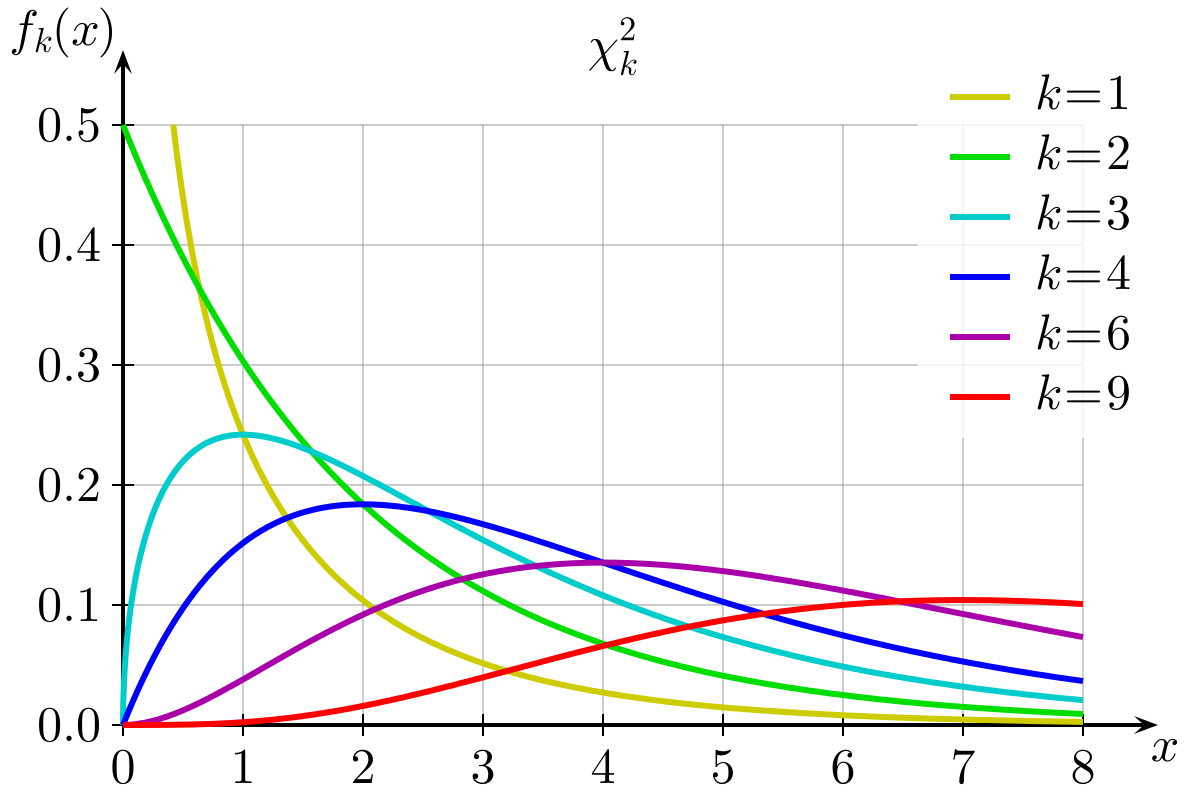
Trong hình trên, chúng ta có thể thấy phân phối Chi-Square cho các bậc tự do khác nhau. Chúng ta cũng có thể quan sát thấy rằng khi bậc tự do tăng thì phân phối Chi-Square xấp xỉ với phân phối chuẩn.
Kiểm tra tính độc lập của hai biến cố bằng Chi-Square
Chi-Square được sử dụng trong thống kê để kiểm tra tính độc lập của hai sự kiện. Với dữ liệu của hai biến, chúng ta có thể nhận được số lượng thực tế quan sát (observed) \(O\) và số lượng kỳ vọng (expected) \(E\). Chi-Square đo lường mức độ chênh lệch của hai đại lượng này.
\[\chi_{c}^{2} = \sum_{}^{}\frac{(O_{i} - E_{i})^{2}}{E_{i}}\]Trong đó:
- \(c\) : Số bậc tự do
- \(O\) : Số lượng thực tế quan sát
- \(E\) : Số lượng kỳ vọng
Khi hai sự kiện độc lập, số lượng được quan sát gần với số lượng dự kiến, do đó chúng ta sẽ có giá trị Chi-Square nhỏ hơn. Vì vậy, giá trị Chi-Square cao cho thấy giả thuyết về tính độc lập là không chính xác. Nói một cách đơn giản, giá trị Chi-Square càng cao thì các sự kiện này càng phụ thuộc vào nhau. Hay nếu ta xem một sự kiện là một đặc trưng của mô hình và sự kiện còn lại là phân loại mà mô hình cần dự đoán (Phản hồi). Khi đó nếu giá trị Chi-Square càng cao thì đặc trưng này càng phụ thuộc vào phản hồi và nó có thể được chọn để đào tạo mô hình.
Đối với lựa chọn đặc trưng bằng Chi-Square, chúng ta mong đợi rằng trong tổng số các đặc trưng được chọn có một phần nhỏ trong chúng vẫn độc lập với lớp phân loại. Tuy nhiên, trong phân loại văn bản hiếm khi các đặc trưng này được thêm vào trong tập đặc trưng trích xuất cuối cùng. Tất nhiên là nó vẫn tốt miễn là phương pháp vẫn xếp hàng các đặc trưng theo tính hữu ích của nó đối với mô hình chứ không phải chỉ sử dụng để đưa ra tuyên bố về sự phụ thuộc hay tính độc lập của các biến trong thống kê.
Các bước thực hiện kiểm tra Chi-Square
Hãy xem xét một tập dữ liệu mà chúng ta phải xác định lý do tại sao khách hàng rời khỏi ngân hàng, hãy thực hiện kiểm tra Chi-Square cho hai biến. Giới tính của khách hàng với các giá trị là Nam/Nữ và Rời khỏi mô tả liệu khách hàng có rời ngân hàng hay không với các giá trị Có/Không. Trong thử nghiệm này, chúng tôi sẽ kiểm tra xem có mối quan hệ nào giữa Giới tính và Rời khỏi.
1. Xác định giả thuyết
Giả thuyết rỗng (\(H_{0}\)): Hai biến đã cho độc lập
Giả thuyết thay thế (\(H_{1}\)): Hai biến đã cho phụ thuộc nhau
2. Xây dựng bảng tương quan
Một bảng hiển thị phân phối của một biến trong hàng và biến khác trong cột. Nó được sử dụng để nghiên cứu mối quan hệ giữa hai biến.
| Giới tính \ Rời bỏ | Có | Không | Tổng |
| Nam | 38 | 178 | 216 |
| Nữ | 44 | 140 | 184 |
| Tổng | 82 | 318 | 400 |
Bậc tự do của bảng tương quan được tính bằng công thức: \((r-1) * (c-1)\) trong đó \(r\), \(c\) là số hàng và số cột. Như bảng trên, ta có:
\[df = (2–1) * (2–1) = 1.\]Trong bảng trên, chúng ta đã tìm ra tất cả các giá trị được quan sát và các bước tiếp theo của chúng tôi là tìm các giá trị kỳ vọng, tính giá trị Chi-Square và kiểm tra mối quan hệ giữa chúng.
3. Tìm giá trị kỳ vọng
Dựa trên giả thiết rỗng là hai biến đã cho độc lập lẫn nhau. Nếu hai biến A, B là biến cố độc lập ta có:
\[P(A \cap B) = P(A) * P(B)\]Hãy tính giá trị kỳ vọng cho ô đầu tiên là những người là Nam và Có rời khỏi ngân hàng.
\[p = p(Yes) * p(Male)\] \[p = (82/400) * (216/400)\] \[p = 0.1107\] \[E_{1} = n * p = 400 * 0.1107 = 44\]Tương tự, ta tính toán được có giá trị \(E_{2}\), \(E_{3}\), \(E_{4}\) và được kết quả như bên dưới.
| Giới tính \ Rời bỏ | Có | Không |
| Nam | 44 | 172 |
| Nữ | 38 | 146 |
4. Tính toán giá trị Chi-Square
\[\chi_{c}^{2} = \sum_{}^{}\frac{(O_{i} - E_{i})^{2}}{E_{i}}\]Sử dụng công thức đã cho ở trên và các giá trị đã tính toán được, ta dễ dàng có giá trị của Chi-Square bằng 2.22
5. Bác bỏ Giả thuyết rỗng
Với độ tin cậy \(95\%\) là \(\alpha = 0,05\), chúng ta sẽ kiểm tra xem giá trị Chi-Square tính được có nằm trong vùng chấp nhận hay từ chối hay không.
Các giá trị Chi-Square chấp thuận có thể xác định bẳng Bảng Chi-Square. Bạn đọc có thể tham khảo tại https://people.richland.edu/james/lecture/m170/tbl-chi.html. Dưới đây là phần của bảng trên.
| df | 0.995 | 0.99 | 0.975 | 0.95 | 0.90 | 0.10 | 0.05 | 0.025 | 0.01 | 0.005 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | — | — | 0.001 | 0.004 | 0.016 | 2.706 | 3.841 | 5.024 | 6.635 | 7.879 |
| 2 | 0.010 | 0.020 | 0.051 | 0.103 | 0.211 | 4.605 | 5.991 | 7.378 | 9.210 | 10.597 |
| 3 | 0.072 | 0.115 | 0.216 | 0.352 | 0.584 | 6.251 | 7.815 | 9.348 | 11.345 | 12.838 |
| 4 | 0.207 | 0.297 | 0.484 | 0.711 | 1.064 | 7.779 | 9.488 | 11.143 | 13.277 | 14.860 |
| 5 | 0.412 | 0.554 | 0.831 | 1.145 | 1.610 | 9.236 | 11.070 | 12.833 | 15.086 | 16.750 |
| 6 | 0.676 | 0.872 | 1.237 | 1.635 | 2.204 | 10.645 | 12.592 | 14.449 | 16.812 | 18.548 |
| 7 | 0.989 | 1.239 | 1.690 | 2.167 | 2.833 | 12.017 | 14.067 | 16.013 | 18.475 | 20.278 |
| 8 | 1.344 | 1.646 | 2.180 | 2.733 | 3.490 | 13.362 | 15.507 | 17.535 | 20.090 | 21.955 |
| 9 | 1.735 | 2.088 | 2.700 | 3.325 | 4.168 | 14.684 | 16.919 | 19.023 | 21.666 | 23.589 |
| 10 | 2.156 | 2.558 | 3.247 | 3.940 | 4.865 | 15.987 | 18.307 | 20.483 | 23.209 | 25.188 |
| 11 | 2.603 | 3.053 | 3.816 | 4.575 | 5.578 | 17.275 | 19.675 | 21.920 | 24.725 | 26.757 |
| 12 | 3.074 | 3.571 | 4.404 | 5.226 | 6.304 | 18.549 | 21.026 | 23.337 | 26.217 | 28.300 |
| 13 | 3.565 | 4.107 | 5.009 | 5.892 | 7.042 | 19.812 | 22.362 | 24.736 | 27.688 | 29.819 |
| 14 | 4.075 | 4.660 | 5.629 | 6.571 | 7.790 | 21.064 | 23.685 | 26.119 | 29.141 | 31.319 |
| 15 | 4.601 | 5.229 | 6.262 | 7.261 | 8.547 | 22.307 | 24.996 | 27.488 | 30.578 | 32.801 |
| 16 | 5.142 | 5.812 | 6.908 | 7.962 | 9.312 | 23.542 | 26.296 | 28.845 | 32.000 | 34.267 |
Ta có bậc tự do (df) bằng 1 (được tính toán dựa vào bảng tương quan phía trên) và \(\alpha = 0,05\) thì giá trị Chi-Square chấp nhận là 3.84.
Nhận thấy giá trị Chi-Square tính được thấp hơn giá trị Chi-Square chấp nhận thì ta chấp nhận giả thiết rỗng. Hay ta có thể kết luận được rằng hai biến cố đã cho độc lập nhau. Vậy nếu ta xem Giới tính là một đặc trưng cần xem xét của mô hình và Rời bỏ ngân hàng hay không là lớp giá trị mô hình cần phân loại, thì ta có thể kết luận, Giới tính không thể được sử dụng để huấn luyện mô hình vì hai biến cố này không có mối liên hệ lẫn nhau.
Sử dụng Chi-Square để lựa chọn đặc trưng cho mô hình phân loại văn bản
Một phương pháp lựa chọn đặc trưng phổ biến được sử dụng với dữ liệu văn bản là lựa chọn đặc trưng với Chi-Square. \(\chi^{2}\) như chúng ta thấy ở trên có thể được sử dụng trong thống kê để kiểm tra tính độc lập của hai biến cố. Cụ thể hơn, trong lựa chọn đặc trưng cho mô hình, chúng ta sử dụng nó để kiểm tra một thuật ngữ cụ thể và một lớp phân loại cụ thể có độc lập hay không.
Cho một văn bản \(D\), chúng tôi ước tính số lượng sau cho mỗi thuật ngữ và xếp hạng chúng theo điểm số của chúng:
\[\chi^2(D, t, c) = \sum_{e_t \in \{0, 1\}} \sum_{e_c \in \{0, 1\}} \frac{ (O_{e_te_c} - E_{e_te_c} )^2 }{ E_{e_te_c} }\]Trong đó:
- \(O\) là tần số quan sát và \(E\) tần số kỳ vọng
- \(e_{t}\) nhận giá trị \(1\) nếu văn bản có chứa thuật ngữ \(t\), \(0\) với trường hợp ngược lại.
- \(e_{c}\) nhận giá trị \(1\) nếu văn bản thuộc lớp phân loại \(c\), \(0\) với trường hợp ngược lại.
Với mỗi đặc trưng (thuật ngữ), một điểm \(\chi^{2}\) tương ứng chỉ ra Giả thuyết rỗng \(H_{0}\) về tính độc lập của hai biến cố (có nghĩa là lớp của văn bản được phân loại không ảnh hưởng đến tần suất xuất hiện của thuật ngữ) nên bị bác bỏ hay sự xuất hiện của thuật ngữ và lớp của văn bản phụ thuộc lẫn nhau. Hay trong trường hợp này, chúng ta sẽ chọn thuật ngữ này làm đặc trưng cho mô hình phân loại văn bản.
Kết luận
Chi-Square nhạy cảm với kích thước mẫu. Các mối quan hệ có thể có ý nghĩa khi chúng không chỉ đơn giản là do một mẫu rất lớn được sử dụng. Ngoài ra, Chi-Square không thể xác định liệu một biến cố có mối quan hệ nhân quả với biến khác hay không. Nó chỉ có thể xác định liệu hai biến cố có liên quan với nhau hay không.. Nói chung, khi giá trị kỳ vọng trong một ô của bảng tương quan nhỏ hơn 5, Chi-Square có thể dẫn đến sai sót trong kết luận. Hy vọng bài viết có thể giúp bạn có cái nhìn tổng quan về phương pháp này và có thể áp dụng nó cho mô hình của bạn.

Mangaldeep Singh is a blogger, software engineer and the main coordinator of this blog, he has lots of ideas and won't hesitate to use them! From ❤️ India.
